DB 이중화(MySQL)
트래픽이 많은 서비스의 경우 당연히 서버 한대로는 감당이 안된다.
그래서 상용 서비스라면 거의 모두, 여러 대의 서버를 띄우고 로드밸런서로 트래픽을 분산시켜 처리한다.
그렇다면 DB는 어떨까?
서버에서 응답을 하기 위한 거의 모든 데이터는 DB에 있을 것이고, 트래픽이 여러 서버로 분산되었다 해도, 모든 서버가 하나의 DB에서 데이터를 처리한다면 결국 응답이 느려지는 건 당연할 것이다.(DB 한대가 슈퍼맨이 아닌 이상)
그래서 서버처럼 각 요청을 여러 DB로 분산시킬 수 있는 DB Replication을 알아보았다. (MySQL을 예시로)
MySQL Replication
MySQL Replication이란?
- 2대 이상의 DBMS에 중복으로 데이터를 저장하고 조회하는 방식이다. (master - slave, master - master, 다중 slave 등등)
- master와 slave에 각각 고유 넘버를 지정하고, 이 고유 넘버로 서로 인식한다.
- 비동기 복제 방식이다.
왜 쓸까?
- 데이터 백업이 가능하다.
- 여러 DB가 있기 때문에 DB가 다운되어도 서비스가 중단되지 않는다.
- 요청을 여러 DB로 분산이 가능하다 (master는 주로 쓰기, slave는 주로 조회)
단방향 Replication 동작 과정
- DB 이용자는 insert, update, delete 등으로 데이터 변경을 요청한다.
- Master는 Binary Log에 변경사항을 기록한다.
- Connection thread는 스토리지 엔진에게 Commit을 수행한다.
- Slave가 I/O thread를 통해 Master에게 Event 요청 시 Master의 Binary log dump thread(Master thread)를 통해 Binary log를 전송한다.
- Slave는 전송받은 파일을 Relay Log에 기록한다.
- Slaves는 SQL thread를 통해 스토리지 엔진에 변경 사항을 기록한다.
Binary log란?
MySQL에서 DDL, DML 과 같은 이벤트 발생 시, 그 이벤트를 기록하는 이진 파일을 Binary Log라고 한다. (show와 select등 조회 문법은 제외된다.) 주요 용도는 아래와 같이 두 가지가 있다.
복제 구성에서 사용
MySQL에서는 복제라는 부하분산 기능을 제공하는데 이때 바이너리 로그를 사용한다. 바이너리 로그는 마스터에서 생성되고 슬레이브에서는 마스터로부터 바이너리 로그를 읽어와서 똑같이 그 이벤트를 실행시켜 동기화한다.
특정 시점 복구에 사용.
데이터베이스를 사용하다보면 어떤 이유로 장애나 크래쉬가 발생할 시 복구를 해야할 때가 있다. 이때 특정 시점으로 돌 아가기 위해 바이너리 로그를 사용할 수 있다.
양방향 Replication 과정
위의 단방향 복제를 이중으로 설정하면 양방향 복제가 가능하다.
각 서버가 master이자 slave가 되는 것이다.
자동 증가값(auto_increment) 문제 해결
복제되는 서버가 여러개이기 때문에 각각의 row를 insert 하게 되면 각 서버의 테이블 기준으로 자동 증가값이 생성되기 때문에 중복값으로 인해서 오류가 발생한다.
이를 해결하기 위해서 각 서버의 자동 증가값이 중복되지 않게 시작 값과 증가값을 수동으로 설정한다.
만약 서버가 3대(서버1, 서버2, 서버3) 이면 아래와 같이 설정해 주면 된다.
| 서버 | auto_increment_offset | auto_increment_increment | 증가값 예시 |
|---|---|---|---|
| 서버1 | 1 | 3 | 1,4,7,10 |
| 서버2 | 2 | 3 | 2,5,8,11 |
| 서버3 | 3 | 3 | 3,6,9,12 |
MMM (Multi - MAster Replication Manager)
- Perl 기반의 Auto Failover Open Source이다.
- MySQL의 master - master 복제 구성의 monitoring / Failover를 수행하는 스크립트 집합이다. (하나의 master에만 쓰기 가능)
- DB 서버에서 에이전트 실행 후 MMM 모니터와 통신하는 방식 (Health check, Failover 수행)
출처
- https://blog.naver.com/love000079/221581285731
- https://mysql-mmm.org
- https://danidani-de.tistory.com/m/28
아래는 잘 정리된 포스트 복사하고, 주석으로 생각 추가
출처 - https://jwdeveloper.tistory.com/215
MMM의 구조
Master (Activce) 와 Master (Standby) 양방향 복제
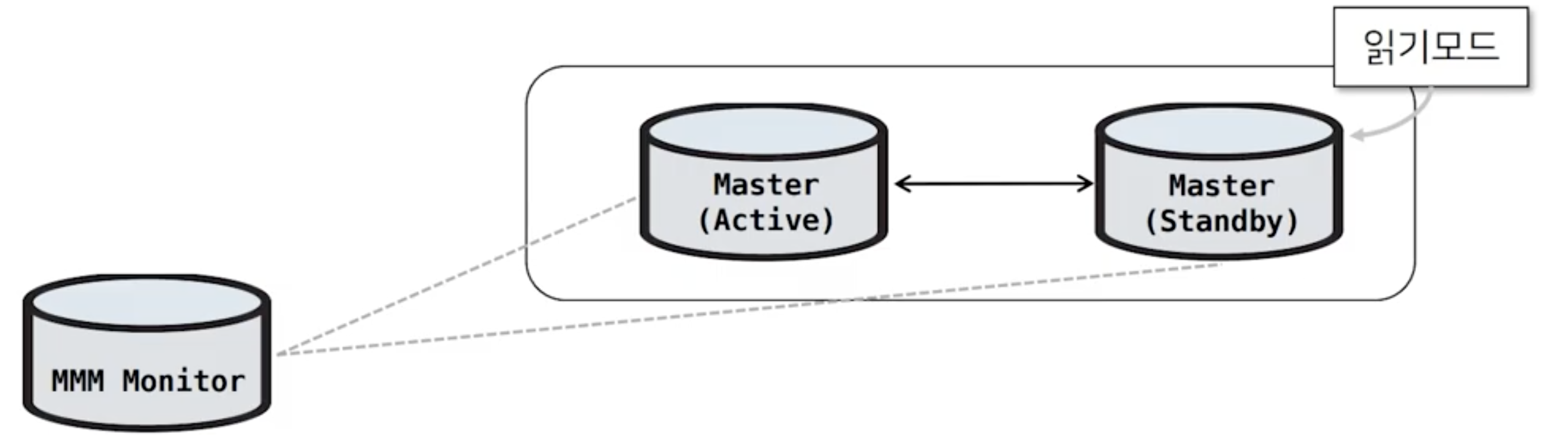
Master (Standby) 는 데이터가 변경되지 않도록 MMM 모니터로부터 읽기모드로 제어된다.
나중에 알아볼 것:
읽기모드로 제어될거면 굳이 Master Standby를 둘 필요가 있나?
그냥 Slave로 두다가 Failover시에 Master로 바꾸면 되지 않나?
실제 Slave로 두는것 vs Master지만 모니터(에이전트)로 읽기모드 통제되다가 바로 master로 투입되는 것의 시간 차이 때문일까?
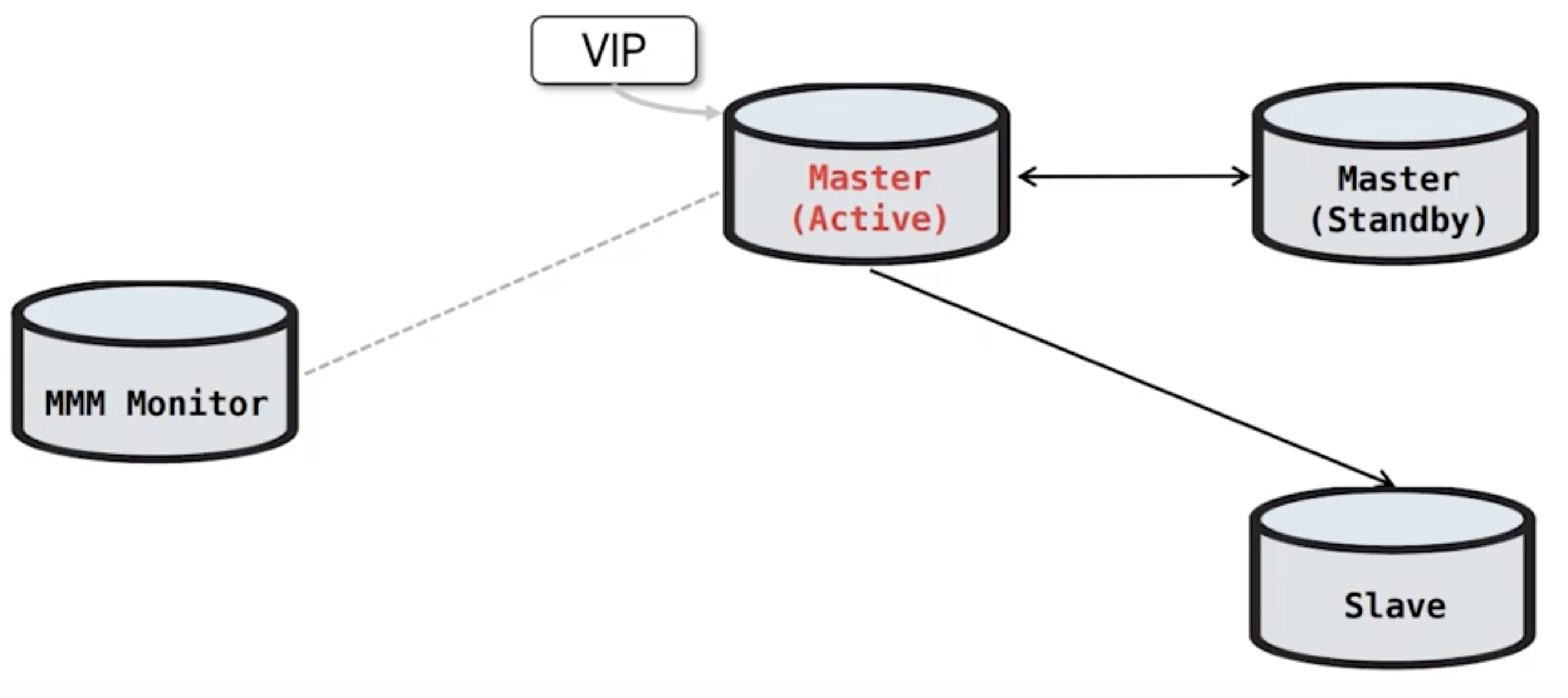
MMM의 구조 - Slave 추가

Slave가 추가된다면 단방향 복제의 Slave가 하나씩 추가되는 구조, 이역시 Master(Active) 를 제외하고는 모두 읽기모드로 제어된다.
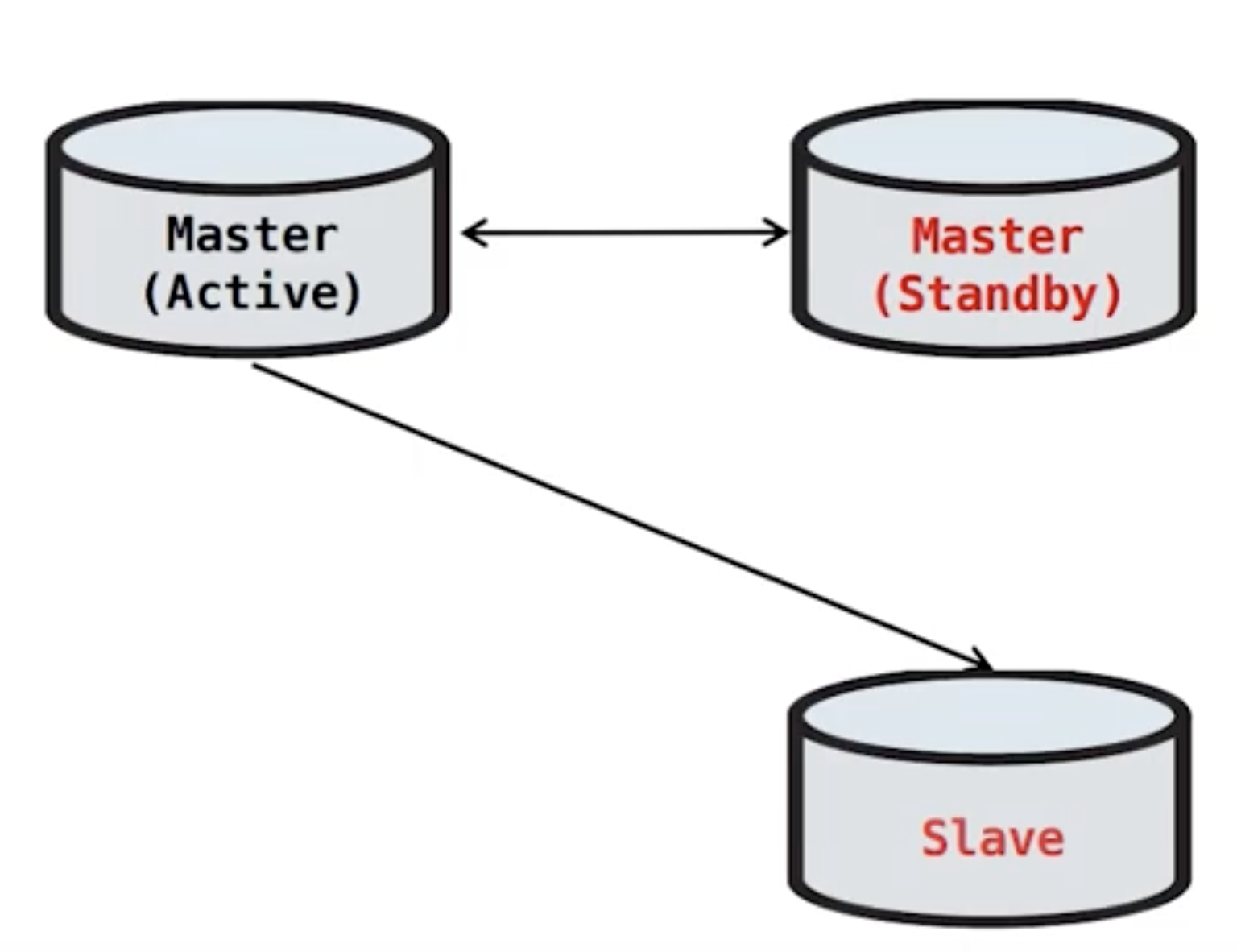
MMM FAILOVER 과정
Master(Active)에서 Master의 역할을 뺏는 작업을 진행한다.
- 읽기모드로 변경
- 세션 킬
- VIP(virtual IP) 회수
Master(Standby) 혹은 Slave로 복제를 제구성한다, 복제를 재구성하기 이전에 복제지연이 있는지 확인한다.
이때 Master(Standby) 기준으로 복제를 진행한다.
Master(Standby) 에 대한 읽기 모드를 해제하고 VIP를 할당한다.
FAILOVER 완료!
복제지연에 대한 설명은 추후 포스트할 예정
MMM FAILOVER의 후속처리
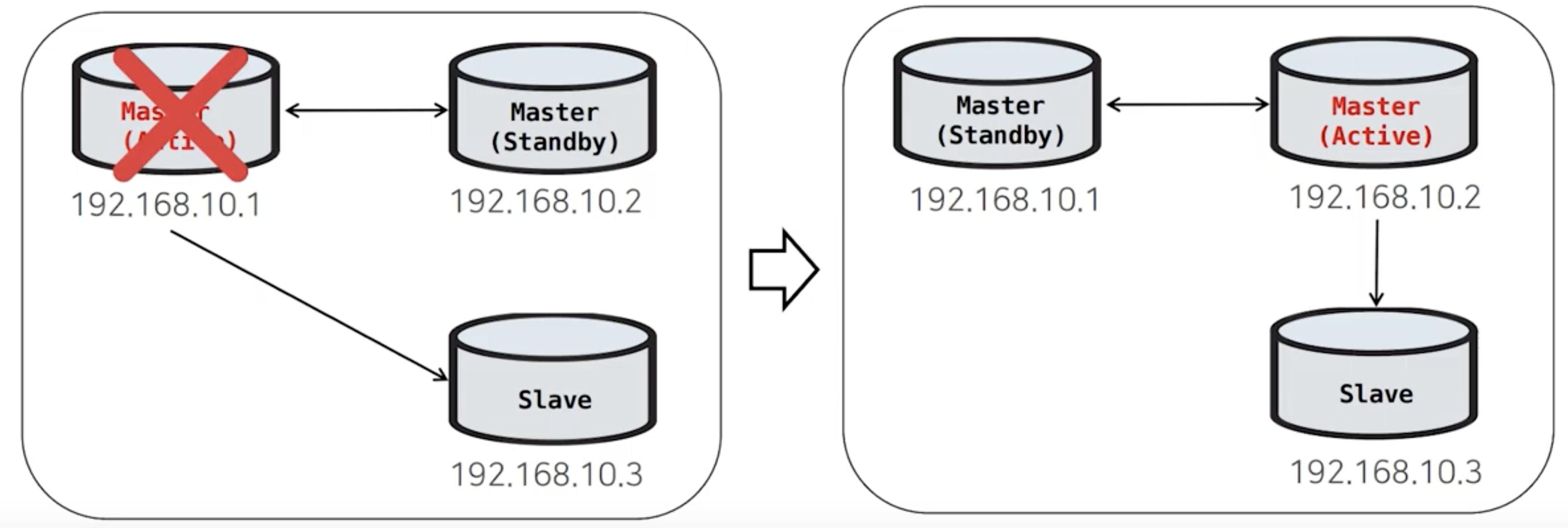
Master(Active)에 장애가 나고 정상적으로 복구가 완료된다면 Master(Standby)로 변경하여 역할만 변경된다.
FAILOVER의 원인
쿼리가 무거운것이 들어와서 OS의 메모리 점유율이 높은 경우
하이퍼 바이저 장애로 인한 경우
MMM FAILOVER 과정에서 복제가 깨지는 경우
상황을 예시로 들자면
INSERT INTO TABLE VALUES (101, 'B');
위의 쿼리를 Master(Active) 에서 진행한다고 가정해보자.
이때 Slave가 101 에 대한 복제를 진행하고 완료 후 Master(Active) 에게 ACK 을 보낸다.
(아직 Master(Standby)는 복제를 하지 못한 상태)
이 당시에 Master (Active)에서 장애가 발생하였다. 그러면 위에서 언급하였듯이 Master (Standby)가Active로 승격되고 101에 대한작업을 다시 진행하게된다.
여기서 문제가 발생한다. Slave는 이미 복제를 통해서 101을 가지고 있으나 Standby에 대한 권한이 올라갔으므로 또 한번의 복제과정이 일어난다. 이때 PK오류가 발생하는 경우가 있다.
Multi Slave 환경에서 미약하지만 복제 Crash 가능성이 존재한다.